
奇美拉 Chimera 使用指南
按照以下步骤,快速上手 Chimera。
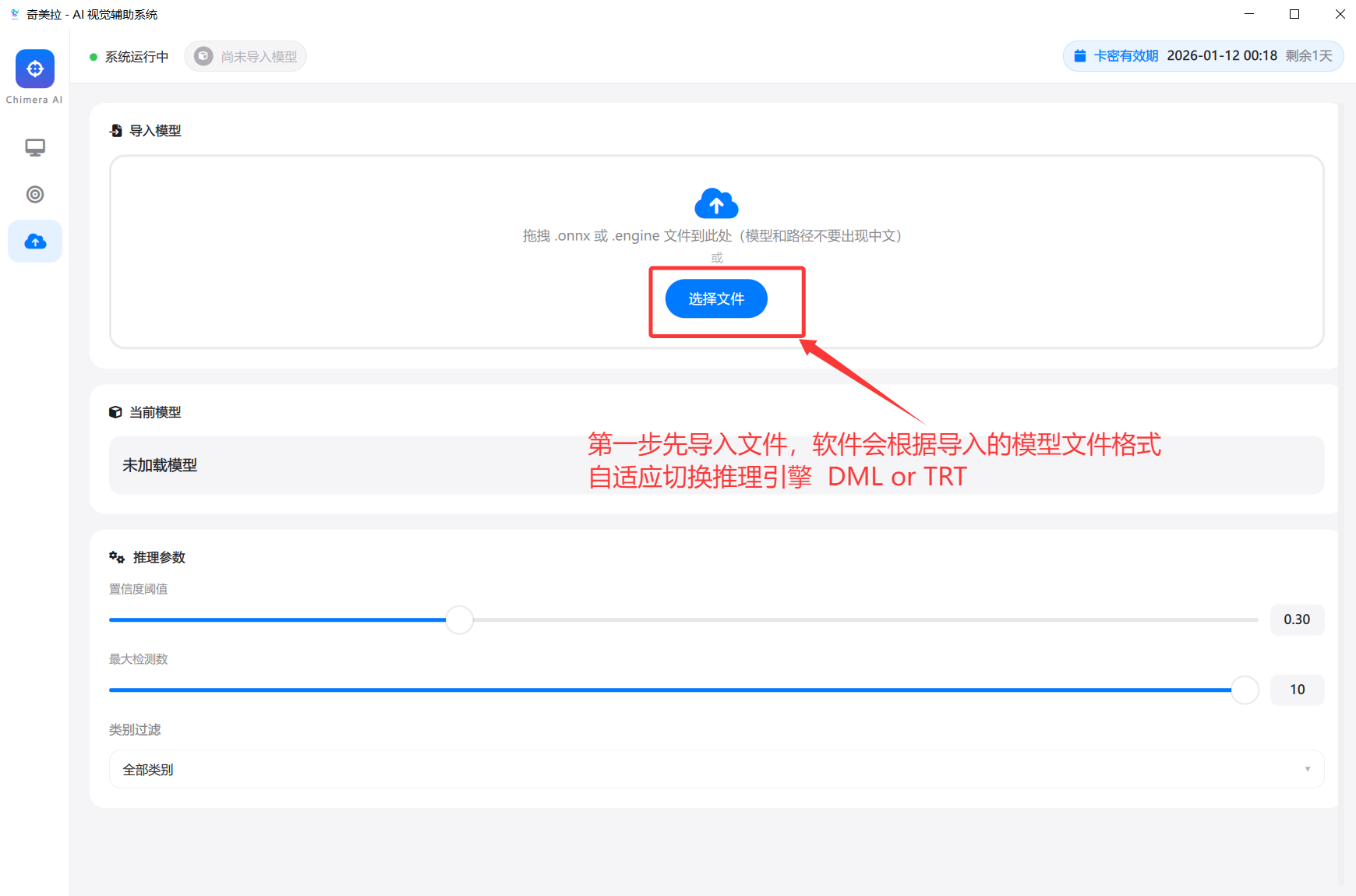
第一步:模型导入
模型格式说明
奇美拉 支持两种推理引擎后端:
- .engine 格式:TensorRT 优化引擎(NVIDIA GPU 专用),性能最佳,延迟最低。
- .onnx 格式:开放神经网络交换格式,通过 DirectML (DML) 通用推理引擎支持跨平台(NVIDIA/AMD/Intel GPU)。
系统会根据导入文件的后缀名自动选择对应的推理引擎:导入 .engine 用 TensorRT,导入 .onnx 用 DirectML。
导入流程
-
打开模型管理界面
在主界面左侧控制栏选择第三个图标进入模型管理界面。 -
拖拽导入模型文件
点击"选择文件"按钮将你的.engine或.onnx文件拖入导入区域。 -
自动选择推理引擎
系统会根据文件后缀自动识别并启动对应的推理后端:.engine文件 → 使用 TensorRT 推理引擎.onnx文件 → 使用 DirectML (DML) 推理引擎
-
加载完成
模型加载成功后,系统会自动读取模型的输入尺寸、输出格式和类别标签。无需任何手动干预。
ONNX 转 Engine(可选)
如果你希望将 .onnx 文件转换为优化后的 .engine 文件以获得更好的性能,
可以使用独立的转换工具(随软件提供):
- 转换工具为独立程序,不依赖主软件运行。
- 转换过程可能需要 30 秒 ~ 2 分钟(取决于模型大小)。
- 转换完成后会在同目录下生成同名的
.engine文件。 - 后续直接导入
.engine文件即可使用 TensorRT 推理。
第二步:ROI 区域与调试
模型导入完成后
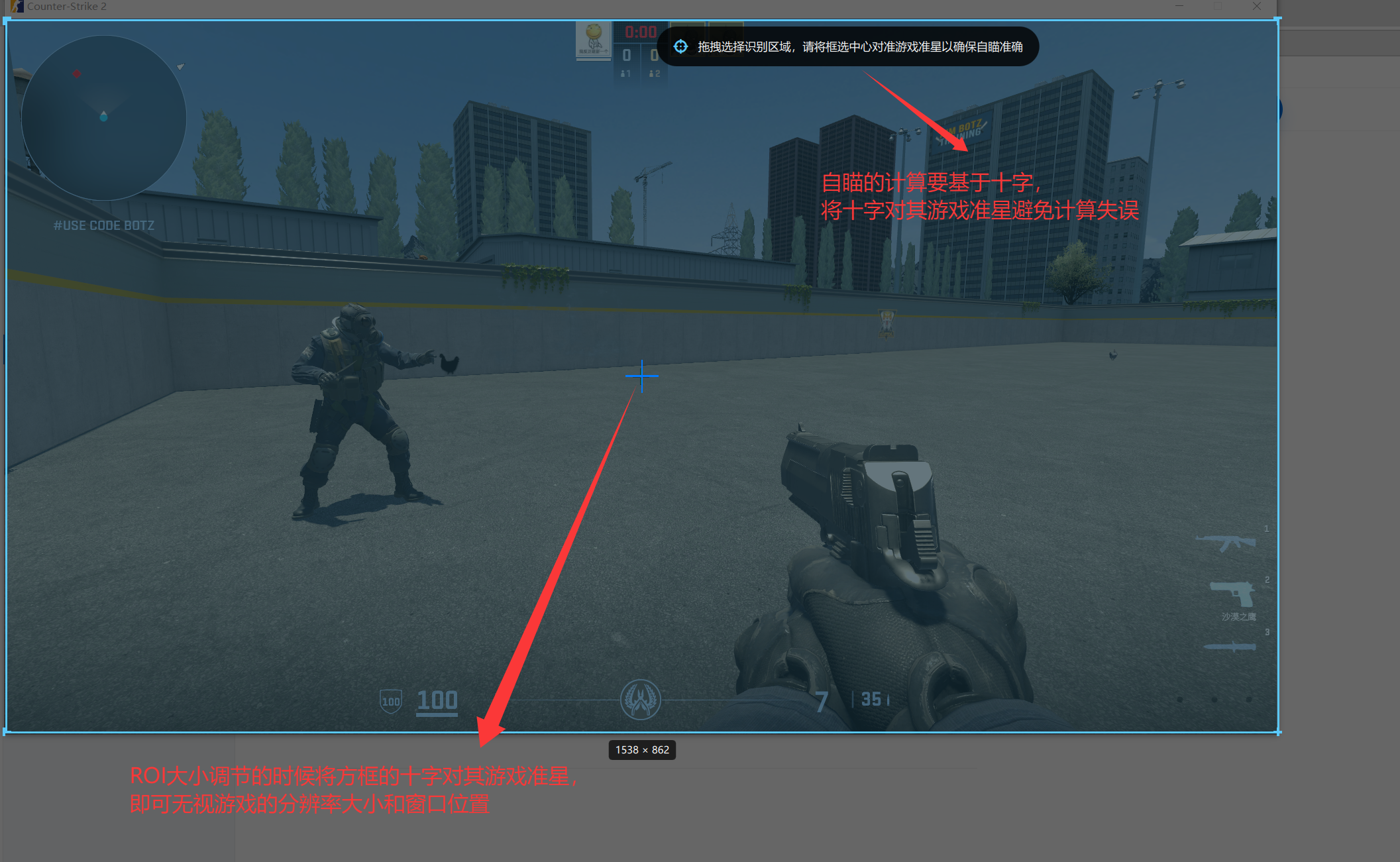
返回主页面窗口,此时你需要选择 ROI(感兴趣区域), 这决定了软件捕获和处理的画面范围。
ROI 区域选择的重要性
📍 准星对齐原则
关键点:选择 ROI 区域时,一定要把游戏内的十字准星对齐到 ROI 选择框的中心。 这是因为自瞄校准计算会以准星位置作为基准点,对齐准星才能保证自瞄精度。
🖼️ 捕获范围的影响
如果不调整ROI区域直接点击调试窗口运行会默认捕获全屏界面, 因为 3D 游戏中存在"近大远小"的透视效应。如果使用默认全屏捕获,远处的敌人像素会非常小. 容易被模型忽略。所以需要调整ROI区域来捕获更大的画面。
实践指导建议:
- 捕获更大的画面: 优点是能检测到更多的敌人,但代价是远处敌人可能识别失败。 适用于需要覆盖大范围的场景。
- 捕获更小的画面: 优点是精确识别,准确度高。但代价是只能看到中心区域。 适用于需要精准击杀的场景。
调试窗口使用
打开调试窗口后,你可以:
- 实时预览:看到模型检测到的目标框和置信度
- 路径规划:看到鼠标路径规划和时间轨迹
- 推理时间:显示单帧推理耗时(ms)
- 检测结果:显示检测到的敌人数量和位置
软件推流/ 采集卡 / 摄像头:如何把画面接入推理?
我们当前的画面获取方式属于 “抓屏 + ROI”:只要画面能在 Windows 桌面上显示出来(例如 OBS、串流软件、播放器窗口、远程桌面窗口等), 你就可以用 ROI 框选该画面区域进行捕获与推理识别。
一句话总结:奇美拉本身不具备接受画面流传输的能力,但是只要“画面能显示在桌面上”软件就能捕获并识别。
- 打开 OBS / 播放器,让采集卡/虚拟摄像头/其它来源的画面在窗口中正常显示。
- 将画面窗口放到屏幕上根据自身的网络情况来决定画面传输的画质,尽可能以低延迟为优先
- 在软件内设置 ROI,框选 OBS/窗口中真实画面区域(尽量不要包含 UI 边框与按钮)。
- 启动推理预览,即可完成“捕获 → 推理 → 输出”。
模型规格、ROI 与性能平衡
本软件的性能表现主要由 GPU 可用性能、模型大小(精度档位) 与 ROI 区域大小 共同决定。 理解三者之间的联动关系,有助于在“识别精度”与“实时性”之间取得平衡。
但“能自适应”不代表“性能无代价”:输入分辨率越大、ROI 越大、模型越大,推理开销也会随之上升。
1) 不同模型大小(精度档位)的区别
常见命名中会包含 n/s/m/l 等档位(不同训练体系命名略有差异),一般可理解为:
- N(Nano,低精度/轻量):速度最快、资源占用最低;对远处/细小目标的识别能力相对弱一些。
- S(Small,均衡):速度与精度较平衡,通常是默认推荐档位。
- M/L(Medium/Large,高精度/更大):精度更强,但需要更多 GPU 计算与显存,推理延迟更高。不建议使用这一类的模型,高精度模型带来的高延迟会严重影响游戏体验
2) ROI 区域与模型输入尺寸的联动
模型的输入尺寸是固定的(例如 320×320)。当你设置 ROI 时,本质上是“截取 ROI → 缩放到模型输入尺寸 → 推理”:
- 缩小 ROI:同样的输入尺寸覆盖更小的画面范围,相当于“局部放大”,更利于远处/小目标呈现;同时减少捕获与预处理开销。
- 放大 ROI:覆盖范围更大,但同样输入尺寸要覆盖更大的画面,细节会被压缩,远处目标可能更难识别;同时开销更高。
3) 游戏占用与软件性能的关系(重要)
当游戏本身占用 GPU 很高时(例如高画质、分辨率高、帧率上限高),软件可用的 GPU 余量会变少。 此时如果再使用 高精度大模型(M/L) 或 较大 ROI,更容易出现推理延迟上升、帧率下降等现象。
性能优化建议(按优先级):
- 降低游戏画质/分辨率或限制 FPS:为推理留出 GPU 余量。
- 切换更轻量模型(N/S):直接降低推理开销。
- 缩小 ROI 区域:减少需要处理的画面范围,同时提升局部细节。
结论:模型越大 + ROI 越大 + 游戏占用越高 = 性能越容易下降。建议优先用 S 档位,并根据实际场景微调 ROI。
参数调试详解
ROI 区域设置完成后,回到主界面的前端控制面板。这里有一系列控制条用来调节软件的检测和运动参数。 下面逐一介绍每个参数的作用和调节方法。
🎯 检测相关参数
📌 置信度 (Confidence)
范围:0.0 ~ 1.0
作用: 检测框的最低置信度阈值。模型每次检测都会给出一个置信度分数(0~1), 只有置信度大于此阈值的检测框才会被显示和使用。
如何调节:
- 值太低(如 0.3): 检测会非常灵敏,但容易产生误检(把游戏中的其他物体误认为敌人)。
- 值太高(如 0.9): 检测会非常严格,但容易漏检(远处或模糊的敌人识别失败)。
-
建议初始值:0.5~0.65
这是一个较平衡的值。如果误检多,往上调;如果漏检多,往下调。
💡 注意事项:不同的模型因为训练的方式和YOLO版本不一样, 可能会导致置信度的不同以及漏检和误检的出现,实际参数需要根据模型进行调整。在正式进入比赛之前请现在训练场通过调试窗口查看模型的精度
🎮 运动相关参数(拟人化控制)
📌 Kp(比例系数 / Proportional Gain)
范围:0.1 ~ 10.0
作用: 控制鼠标移动的响应速度。数值越大,鼠标移动到目标的速度越快。 这是 PD 控制中的比例项,决定了系统对误差的反应程度。
如何调节:
- 值太小(如 0.5): 鼠标移动缓慢,反应迟钝,容易漏掉快速移动的目标。
- 值太大(如 8.0): 鼠标移动过快,容易超调,导致瞄准点在目标周围抖动。
-
建议初始值:1.5~3.0
根据游戏的鼠标灵敏度和目标运动速度微调。
📌 Kd(微分系数 / Derivative Gain)
范围:0.1 ~ 10.0
作用: 控制鼠标移动的平滑度和稳定性。数值越大,运动越平稳,抖动越少。 这是 PD 控制中的微分项,用来阻尼系统的振荡。
如何调节:
- 值太小(如 0.5): 阻尼效果弱,鼠标容易抖动和超调,显得"机械"。
- 值太大(如 8.0): 阻尼过强,鼠标反应变慢,容易滞后目标。
-
建议初始值:1.0~2.0
与 Kp 配合使用,目标是"快速但平稳"地到达目标。
💡 调试技巧:通常先固定 Kd,调节 Kp 找到合适的响应速度; 然后固定 Kp,调节 Kd 消除抖动。最终目标是"像真人玩家一样移动"。
📌 到达时间 (Duration / Move Time)
范围:50ms ~ 1000ms
作用: 从当前鼠标位置移动到目标位置需要的总耗时。这是贝塞尔曲线运动的时间参数。
如何调节:
- 值太小(如 50ms): 移动非常快,接近瞬间移动,容易被反作弊系统检测。
- 值太大(如 800ms): 移动太慢,目标可能已经移动了,导致自瞄失效。
-
建议初始值:100~200ms
这个范围模拟真人反应时间和手感。
⚠️ 重要:这个参数并非越快越好,对于人眼来说200ms-400ms是最合适的, 过短的时间会因为鼠标输入限制导致处理失败,可能会出现甩飞的副作用,如果出现画面甩飞请尝试提高路径时间,并调高Kd阻尼作为保护
🔄 调试流程建议
为了高效地调出最佳参数,建议按以下顺序调节:
| 调试步骤 | 操作 | 目标 |
|---|---|---|
| 1️⃣ 置信度 | 从 0.3 开始,在调试窗口观察 Overlay。如果误检多就往上调,漏检多就往下调。 | 能够在调试窗口中显示出检测的方框 |
| 2️⃣ 最大检测数 | 根据游戏场景人数设置(见上文说明) | 根据需要进行设置 |
| 3️⃣ 到达时间 | 从 200ms 开始,拉动目标测试鼠标跟踪。鼠标移动不是越快越好,过快可能会导致撕裂画面而甩飞,建议在200ms-400ms之间调整。 | 鼠标能跟上目标,看起来自然 |
| 4️⃣ Kp | 从 500开始,逐步调节。观察鼠标是否能快速响应目标变化。 | 响应速度快,但不过度超调 |
| 5️⃣ Kd | 从 350开始,逐步调节。观察鼠标移动是否平稳,有无抖动。 | 运动平稳自然,无明显抖动 |
| 6️⃣ 微调 | 不同的游戏有不同的人物画面效果,需要根据实际情况进行微调。 | 达到理想的隐蔽性和有效性 |
⚙️ 参数调试的实用建议
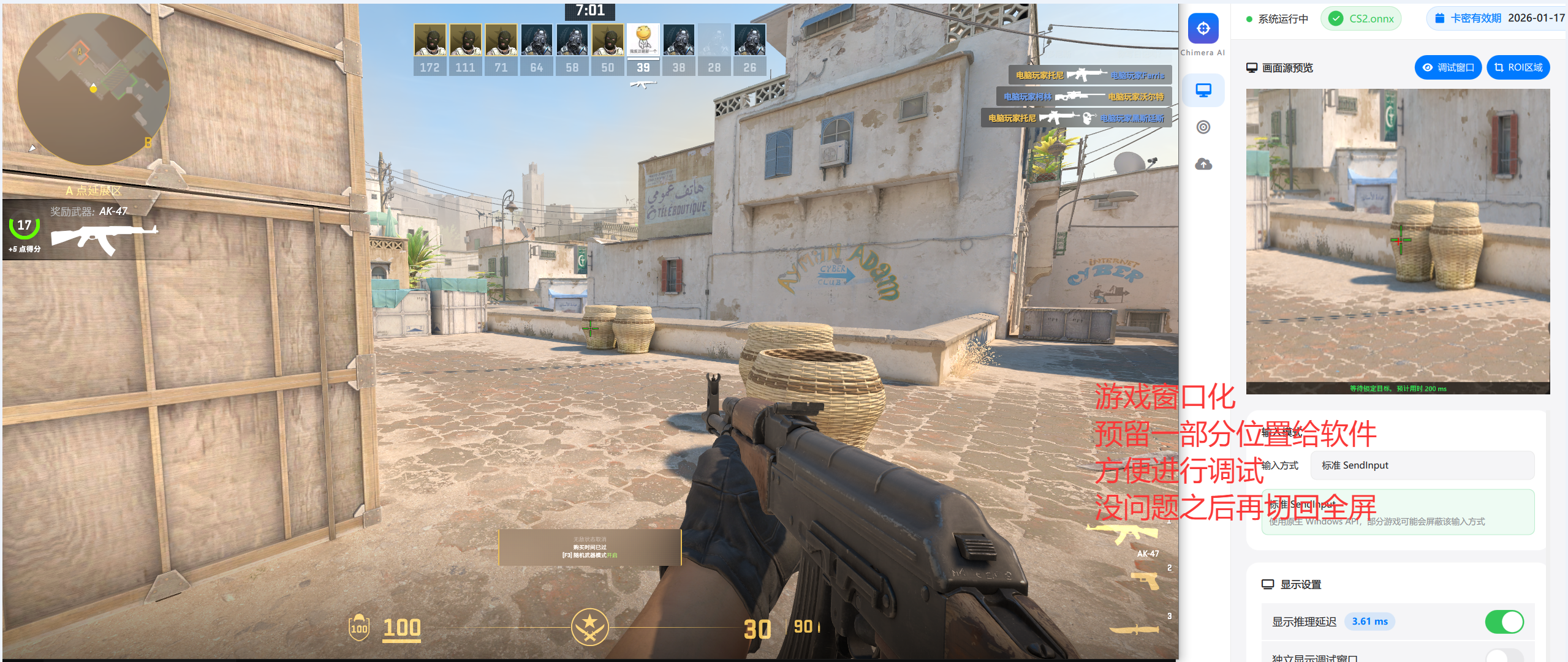
- 实时调试: 将游戏窗口化,预留一部分屏幕空间给软件,在调试窗口中实时观察参数变化的效果。不要盲目调节参数。
- 小幅调节: 每次调节参数时,只改变 10~20% 的幅度。大幅度改变容易过度调节。
- 单一变量法: 同时调节多个参数容易混乱。建议先固定其他参数,只改变一个,观察效果。
- 开始前的调试: 首次开始游戏之前建议先让游戏窗口化并留出一部分空间给软件来进行参数调试,没问题之后再全屏游戏
双机配置指南
什么是双机模式?
双机模式将"游戏机"和"推理机"分离。游戏机只负责游戏运行,推理机负责 AI 计算和操作投递。 这样可以实现物理级的反作弊规避,游戏机内部完全没有恶意进程或内存读取。
双机的推理性能更高
核心原因就是:推理机不需要渲染游戏。在单机模式下,游戏渲染往往会占用大量 GPU(甚至接近满载), 这会挤压 AI 推理可用的 GPU 资源,导致推理延迟上升、帧率波动。
- 推理机 GPU 更“空闲”:不跑游戏渲染,只跑 DXGI 捕获/预处理/TensorRT 推理,吞吐更稳定。
- 可更大胆使用高规格模型:在推理机资源充足时,使用更高输入分辨率或更大模型带来的延迟上涨会更可控。
- 稳定性更好:游戏机的 GPU/CPU 负载变化不会直接影响推理机的推理队列与延迟曲线。
双机模式下:推理机需要单独运行 OBS 吗?
不一定。原因很简单:我们当前的画面输入方式是 抓屏 + ROI, 所以推理机必须先把“来自游戏机/采集卡/虚拟摄像头/串流”的画面显示到 Windows 桌面上,软件才能捕获。
- 采集卡方案:推理机运行 OBS,把采集卡画面显示在预览/投影窗口里 → 用 ROI 框选画面区域 → 推理。
- 串流/播放方案:推理机运行播放器/接收端,让画面在窗口里显示 → ROI 框选该窗口中的画面区域 → 推理。
硬件要求
- PC1(游戏机):任意配置,能运行游戏并传输画面即可
- PC2(推理机):任意GPU,同时能让画面显示出来即可,软件只需要ROI捕获画面即可
- 采集卡或流媒体卡:用于将游戏画面从 PC1 传输到 PC2
- MAKCU/KMBOX 硬件模拟器,用于从 PC2 投递鼠标键盘操作回 PC1
配置步骤
加入社区获取更详细的配置教程
罗技 G HUB 配置 (单机方案)
原理说明
罗技 G HUB 方案通过调用罗技官方驱动提供的鼠标模拟接口进行操作。相比于 Windows 标准的 SendInput,
由于其操作是由驱动层级发出的,在单机环境下具有更好的兼容性和隐蔽性。
- 必须在电脑上安装 Logitech G HUB 软件。
- 版本建议: 建议使用 2021.3 ,并关闭自动更新
- 硬件要求: 不需要拥有罗技硬件,驱动安装后即可提供虚拟接口。
配置步骤
- 安装驱动:安装罗技G HUB 2021.3版本,相关安装包会随同程序一起发放
- 软件设置: 确保 G HUB 软件在后台开启,选择GHub作为输入
- 验证: 在调试窗口中观察路径规划,若鼠标能随之移动则说明调用成功。
硬件盒子配置 (双机方案)
硬件盒子是实现“物理隔离”和“极致隐蔽”的核心设备。软件支持目前主流的三种硬件控制方案:
1. MAKCU 控制器
固件版本: 建议使用固件版本 > 3.7 的硬件。
配置要点:
- MAKCU 串口号: 在设备管理器中确认硬件对应的 COM 端口(例如 COM1)。
- 波特率: 统一设置为
115200。 - 特点: 原生 HID 模拟,响应极快,是双机部署的首选推荐。
2. KMBOX B+ (Pro)
兼容性: 若使用旧版 MAKCU (固件 < 3.7) 或标准 KMBox B+ 硬件,请选择此模式。
配置要点:
- KMBOX 串口号: 同样需在设备管理器中确认 COM 端口(例如 COM8)。
- 波特率: 统一设置为
115200。 - 注意: 确保接线正确,B+ 盒子的控制端需连接至游戏机。
3. KMBOX NET (网络版)
通信原理: 通过网线直接与盒子通信,无需通过本机的 USB 串口投递指令。
配置要点:
- KMNET IP: 输入盒子的 IP 地址(默认通常为 192.168.2.188,请查看盒子屏幕显示)。
- KMNET 端口: 输入通信端口(默认为 1234)。
- KMNET UUID: 输入硬件唯一的 UUID 识别码。
- 注意: 其他品牌的盒子如果是KMNET协议,也同样适配。只要使用的是KMNET协议,并不要求特定盒子固件类型
注意事项
注意事项
- 本软件需要调用GPU来进行识别和推理,部分游戏在运行的时候会占用大量GPU资源导致本软件的性能下降 如果在使用的过程中发现推理速度不高(20ms以上)请降低游戏画质以空闲GPU资源给软件,或者使用双机模式在副机上进行推理
常见问题 (FAQ)
Q: 模型文件应该放在哪里?
A: 可以放在任意位置。第一次导入后,系统会在该文件同目录下生成 .engine 文件。建议创建一个专门的 models 文件夹来管理。
Q: 为什么 ONNX 转 ENGINE 很慢?
A: TensorRT 的编译过程需要对模型进行优化和编译,第一次会比较慢。完成后会生成 .engine 文件,下次启动就直接加载,无需再次转换。
Q: 支持哪些游戏?
A: 软件只是基于画面进行识别和推理,所以理论上支持所有的游戏,只要导入对应的模型即可
Q: 双机模式一定要采集卡吗?
A: 只要能够让软件识别到画面输出即可,例如OBS、采集卡,摄像机。使用采集卡可以获取更低的延迟,但并不是必须。
